1.拉格朗日乘数法
1.1 基本定义
拉格朗日最早提出的是针对等式约束的拉格朗日乘数法
考虑如下的优化问题:
$$ \begin{aligned} & \text{minimize} \quad & f_0(x)& \\\\ & \text{subject to} \quad & h_i(x) & = 0, \quad i=1, \cdots, m \end{aligned} $$则有拉格朗日函数:
$$ L(x, \nu) = f(x) + \sum_{i=0}^m \mu_i h_i(x) $$其中$\mu$为对应等式约束的拉格朗日乘子(或拉格朗日乘数)。拉格朗日函数的形式化表达会在稍后介绍。
拉格朗日乘数法的一般求解步骤如下:
- 构造拉格朗日函数
- 求取拉格朗日函数对每一个变量的偏导(梯度),令其为0。这一步并不要求函数是凸的
- 求解
2.中得到的方程组,得到最优点
具体的原理在稍后的小节介绍
由此可见,拉格朗日乘数法在一定程度上将问题转化为了无约束优化问题,整个求解步骤无需额外考虑约束方程带来的影响,其效果已经被拉格朗日函数考虑在内
1.2 最优性条件
最优性必要条件为:在局部最优解 $x^\*$ 处要满足:
1.2.1 平稳性条件
最优点一定是(拉格朗日函数的)驻点
$$ \nabla_x L(x^\*, \mu^\*) = \nabla f(x^\*) + \sum_j \mu_j^\*\nabla h_j(x^\*)=0 $$补充概念:驻点与鞍点
驻点: 对于函数$\mathbb{R}^n\rightarrow \mathbb{R}$,若在点$x^\*$处梯度为零,即:
$$ \nabla f(x^\*) = 0 $$则称$x^*$为函数$f$的驻点
当在$x^*$的某个邻域内
- 有$f(x^\*) \geq f(x)$,则$x^\*$为局部极大值点
- 有$f(x^\*) \leq f(x)$,则$x^\*$为局部极小值点
若以上两者都没有,则此时$x^\*$是$f$的鞍点。为鞍点时,$x$不是最优点
1.2.2 满足等式约束
$$ h_i(x^*) = 0 $$1.3 实际举例
实际求解需要注意如下条件:
- 拉格朗日乘数法不能处理含有不等式约束的问题,强行取等将导致结果不准确
- 所有拉格朗日乘子本身也是待求解参数,需要将其与变量值等同看待
例1
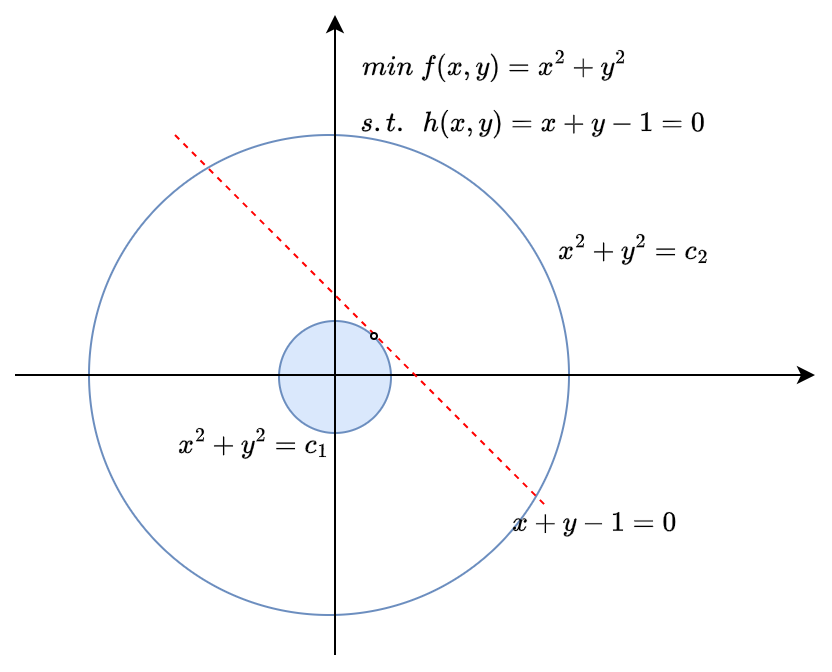
它的拉格朗日函数为:
$$ L(x, y, \mu) = f(x, y) + \mu_1 h_1(x) = x^2+y^2 + \mu (x + y - 1) $$$$ h_1(x) = x+y-1=0 $$对拉格朗日函数的每一个变量求偏导数
$$ \begin{cases} \frac{\partial L}{\partial x} = 2x+\mu = 0 \\\\ \frac{\partial L}{\partial y} = 2y + \mu = 0 \\\\ \frac{\partial L}{\partial \mu} = x+y-1 = 0 \end{cases} $$分步求解该方程组:
$$ \begin{cases} 2x = -\mu \\\\ 2y = -\mu \\\\ x+y=1 \end{cases} $$$$ \begin{aligned} \mu &= -1\\\\ x &= \frac{1}{2} \\\\ y &= \frac{1}{2} \end{aligned} $$求解顺序通常为 变量→拉格朗日乘子,优先处理约束方程
此时,$(x, y)$虽然不是优化目标的驻点,但却是问题的拉格朗日函数的驻点,其在是驻点的同时满足约束条件。
2.拉格朗日函数
将拉格朗日乘数法引入不等式约束并进一步抽象可以得到现代框架下的拉格朗日函数。
考虑如下的最优化问题:
$$ \begin{aligned} & \text{minimize} \quad & f_0(x)& \\\\ & \text{subject to} \quad & g_i(x) &\leq 0, \quad i=1, \cdots, m \\\\ & & h_i(x) & = 0, \quad i=1, \cdots, p \end{aligned} $$它的拉格朗日函数定义为:
$$ L(x, \lambda, \mu) = f(x) + \sum_{i=1}^m \lambda_i g_i(x)+ \sum_{j=1}^p \mu_jh_j(x) $$其中$\lambda_i$是第$i$个不等式约束($g_i(x) \leq 0$)对应的拉格朗日乘子(或拉格朗日乘数),$\mu_i$是第$i$个等式约束($h_i(x)=0$)对应的拉格朗日乘子。向量$\lambda$和$\mu$称为对偶变量或者问题的拉格朗日乘子向量
可见,当不存在不等式约束时,问题会退化为传统乘数法中的拉格朗日函数。
3.KKT条件(Karush-Kuhn-Tucker条件)
KKT条件是一种判定非线性优化问题最优点的条件。任何情况下,KKT条件是最优点的必要条件,当问题为凸时其为充要条件。
注:此处默认最优点满足常见约束规范(Constraint Qualification)。病态问题不满足CQ。
对于是否为凸和是否满足CQ的情况如下:
| 问题类型 | 是否满足CQ(无病态) | 必要性(局部最优→KKT条件) | 充分性(KKT条件→局部最优) |
|---|---|---|---|
| 凸问题 | ✓ | ✓ | ✓ |
| 凸问题 | ✗ | ✗ | ✓ |
| 非凸问题 | ✓ | ✓ | ✗ |
| 非凸问题 | ✗ | ✗ | ✗ |
KKT条件包含但不限于拉格朗日乘数法中的两个条件(平稳性条件,原始可行性条件),其完整的表述如下:
3.1 平稳性条件(一阶条件)
$$ \nabla_x L(x^\* , \lambda^\*, \mu^\*) = 0 $$也可以表达为
$$ \nabla f(x^*) + \sum_{i=1}^m \lambda_i^\* \nabla g_i(x^\*)+ \sum_{j=1}^p \mu_j^\*\nabla h_j(x^\*) = 0 $$KKT条件的平稳性条件定义直接由凸函数的一阶条件定义扩展开来。
拉格朗日乘数法的求解直接使用了该条件的必要性,即若存在最优解,则它必然满足梯度为0的方程组(即满足CQ)。
3.2 原始可行性条件(约束部分)
即最优点一定满足问题的所有约束
$$ \begin{aligned} g_i(x) &\leq 0 \\\\ h_j(x) &= 0 \end{aligned} $$拉格朗日乘数法通常从这一部分着手求解方程组。
3.3 对偶可行性条件
即函数的梯度方向不与优化方向发生冲突,即不会损伤目标函数。
$$ \lambda_i \geq 0 $$该条件也直接与经济学中的影子价格息息相关,将在稍后介绍。
对于等式约束部分,由于其为双侧的,故而对梯度的方向无内在限制,求解时也无需额外考虑。
概念延伸:影子价格
影子价格又称最优计算价格或者计算价格,其能够反应投入物与产出物的真实经济价值,反映市场供求情况。
若考虑以下的资源优化问题:
$$ \begin{aligned} \min \quad &f(x) \\\\ \text{s.t.} \quad & g_i(x) \leq b_i \quad \text{(资源约束)} \\\\ & h_j(x) = c_j \end{aligned} $$其中,$b_i$可以用于指示某种资源限制,例如某发电厂的最大发电限额。
该问题可以有如下的拉格朗日函数:
$$ L(x, \lambda, \mu) = f(x) + \sum \lambda_i(b_i - g(x)) + \sum \mu_i (c_j - h(x)) $$求解过程中,求取拉格朗日乘子即可得到一个影子价格,或者由如下方式近似:
$$ \lambda_i^\* = \frac{\partial f^\*}{\partial b_i} \approx \frac{f^\*_{\text{new}} - f^\*}{\Delta b} $$即,在约束右项中新增一个细微值$\Delta b$来计算梯度。其中$f_{\text{new}}$需要重新求解
注意:
- 当且仅当约束为线性且$\Delta b$较小时才准确
3.4 互补松弛可行性条件
$$ \lambda^\*_ig_i(x^\*) = 0 $$该可行性实际上是对不等式约束中原始可行性条件和对偶可行性条件的交界,即不等式约束的乘子或者约束必然有一个为0
- 当约束活跃(紧):$g_i(x^\*)=0$,此时无论$\lambda_i$为何值时,该条件满足,该约束起到限制作用
- 当约束非活跃时(松):$g_i(x^\*) < 0$,此时需要$\lambda_i = 0$,即该约束并没有起到实际的限制作用
4.拉格朗日对偶
4.1 基本定义
考虑如下的最优化问题:
$$ \begin{aligned} & \text{minimize} \quad & f_0(x)& \\\\ & \text{subject to} \quad & g_i(x) &\leq 0, \quad i=1, \cdots, m \\\\ & & h_i(x) & = 0, \quad i=1, \cdots, p \end{aligned} $$由此可得其拉格朗日函数
$$ L(x, \lambda, \mu) = f(x) + \sum_{i=1}^m \lambda_i g_i(x)+ \sum_{j=1}^p \mu_jh_j(x) $$对于其拉格朗日对偶函数的定义为
$$ g(\lambda, \mu) = \inf_{x\in{\mathcal{D}}} L(x, \lambda, \mu) $$其中$\inf$表示求下确界,$\mathcal{D}$是满足约束条件的定义域。
求取对偶函数可围绕定义中的"下确界"展开,通常有如下方法:
以$L(x, \lambda) = x^2 + \lambda x + 1$ 为例
- 偏导法:对自变量求偏导以求得极值点。这种方法只能在拉格朗日函数为凸时才能使用,但也是最稳的方法,SVM的大多数核都符合这个条件
- 瞪眼法:即尝试直接寻找极值点,或将函数改造成可肉眼寻找极值点的形式,以避免复杂的机械性极值点求取。这种方法只能应用在二次函数、ReLU等结构简单的函数中
显然,在$x=-\frac{\lambda}{2}$可以取得最小值,代入可得到对偶函数
下确界
设$S \subseteq \mathbb{R}$ 是一个非空集合,若$\alpha$是$S$的下界,且$\alpha$是其中最大的一个,则称$\alpha$是$S$的下确界。
下确界通常是可以无限逼近但无法到达的点,例如$(0, 10]$中的0,但也可以是一个可以到达的点,如$[0, 10]$中的0。